
Blog: Scraping Steam with Scrapy
2024/06/25
Introduction
This blog contains a revised and expanded guide on how to extract reviews, general game information, and news from Steam webpages using Scrapy. The code is available in a GitHub repository. It's a fork and update of the code produced for an original guide, titled Scraping the Steam game store with Scrapy, which has become slightly outdated due to changes on the Steam website. I'd like to thank the author of initial blog post for an introduction to Scrapy and a great starting point for this project. The original code with fixes is available in a separate branch.
Why scraping?
The world wide web is filled with data. While some of it is gathered into datasets or available through APIs, most exist only in publicly available HTML format. This is why I had this skill on my to-learn list. It's a powerful tool for creating new datasets from scratch and enriching existing ones.
Legal and ethical considerations
Web scraping isn't inherently illegal, but it's not always encouraged by website owners. It becomes illegal if scraping is explicitly prohibited in website terms of service. Many websites also have a file named robots.txt. This file instructs bots on how to interact with the website. Disrespecting it isn't necessarily illegal, but it's considered unethical.
I found no prohibitions (or express allowance) of scraping in Steam's terms of agreement. According to their robots.txt, they are quite permissive with scraping public data, since they allow bots to access most of their website. They even provide APIs for certain data. Using APIs is generally superior to scraping because APIs are usually more stable and reliable way to access data.
How to read this blog?
As mentioned, this blog is an update to the slightly outdated original guide. I suggest that you read the original since it explains some basic Scrapy concepts like crawlers and item loaders. This blog will focus on concepts that I found important and either weren't explained or not explained in enough detail for my scraping. I'll assume you're familiar with concepts covered in the original guide and skip explanations already provided there.
The content is split into two parts. The first part describes the fixes applied to the outdated code from the original guide. The second part expands the original code by adding a database and using web API to gather news.
Code adaptations
Scrapy middlewares
I try to think of Scrapy as a well-oiled machine. It is designed to do the scraping for you, with minimal input. To do that, you have to understand the architecture, so that you know which setting or function to modify.
Middlewares are frameworks of hooks designed to plug custom functionality. There are two different middlewares, spider middleware, and downloader middleware. Their main intent is to preprocess requests before they get to the spider/downloader and postprocess the responses.
To use middlewares, you need to adjust the SPIDER_MIDDLEWARES or DOWNLOADER_MIDDLEWARES setting. These are dictionaries where the keys are the paths to your custom middleware classes, and the values are priority numbers that determine the order of execution. For preprocessing tasks (like adding headers), lower numbers are processed first. For postprocessing tasks (like cleaning data), higher numbers are processed first.
There are several built-in middlewares in Scrapy. You can find information about them in SPIDER_MIDDLEWARES_BASE and DOWNLOADER_MIDDLEWARES_BASE settings. You may disable certain built-in middleware by setting its key to None.
Example
Steam's age verification process has been updated, causing the original code to frequently return TypeError: Request url must be str, got NoneType. This error occurred because the original approach relied on handling redirects for age confirmation that were modified. Instead, I found it easier to add the necessary cookie to each request. To achieve this, a new downloader middleware named AddAgeCheckCookieMiddleware was created.
We add this middleware to the steam/settings.py file with priority of 652:
DOWNLOADER_MIDDLEWARES = {
"steam.middlewares.AddAgeCheckCookieMiddleware": 652,
}
This priority is assigned, because we want this middleware to be triggered before the built-in CookiesMiddleware, which manages other cookies received from the web server (list of default priority numbers is shown in DOWNLOADER_MIDDLEWARES_BASE).
The code for the middleware is located in steam/middlewares.py:
class AddAgeCheckCookieMiddleware(object):
@staticmethod
def process_request(request, spider):
if spider.name == 'products' and not request.cookies:
request.cookies = {"wants_mature_content": "1", "lastagecheckage": "1-0-1985", "birthtime": '470703601'}
There are various entry points for customization of Scrapy middlewares. In this case, we use the process_request method to modify the request object before it's sent to Steam's servers.
Other adaptations
Deprecated code
Some Scrapy functions used in the original code have been deprecated. They are still functional but might be removed in future Scrapy versions. To address this, we need to replace the following line in steam/items.py file:
from scrapy.loader.processors import Compose, Join, MapCompose, TakeFirst
with:
from itemloaders.processors import Compose, Join, MapCompose, TakeFirst
Adapted fields
Several fields required adjustments due to changes on the Steam website. You'll find the details of these modifications in the commit changes for the following files:
steam/spiders/product_spider.pysteam/spiders/review_spider.pysteam/items.py
A quick summary of changes:
- I was scraping from Europe, which is why the code was adapted to handle prices in EUR with comma separators. If you have different currency format, you might need to adjust the
str_to_floatfunction insteam/items.py. - Rearranged divs within
specs. n_reviewshas been modified and now doesn't contain text "reviews" at the end.- New fields
description_about,description_reviews, andfound_awardingwere added, whilefound_unhelpfulwas removed. - The code can now handle two
user_idformats -.*/profiles/<PROFILE_ID>/and.*/id/<PROFILE_ID>/ - The scraper ignores broken review URLs like http://steamcommunity.com/app/1256/reviews/?browsefilter=mostrecent&p=1.
Extending scraper
SQLite database
I wanted to store scraped data in a relational database because it is one of the most established and widely used methods for data storage and management. SQLite is a popular choice for such tasks, especially when dealing with projects that don't require a large-scale database server. I prefer this SQL database engine mostly because it is self-contained - meaning that it has very few dependencies and runs on any operating system with almost no use of external libraries. Put simply, it is easy to install and use.
Schema
The code that handles database connection and SQL queries is located in steam/sqlite.py. After examining the JSON files from the original code, I designed the following database schema:
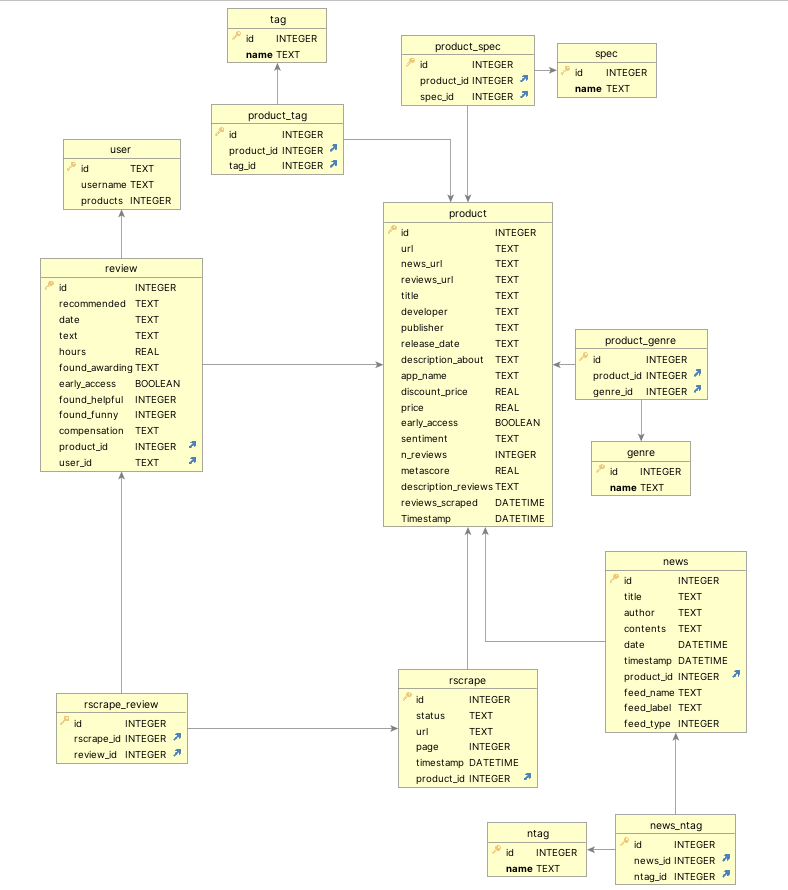
Storing data into tables
While I won't delve into every detail, here's a high-level overview of the main tables and their relationships, reflecting the three sources used:
- Product tables - The central table
productstores information about games and applications on Steam. Other tables that are strongly related to this one aretag,genreandspec. - Review tables - The
reviewtable stores data extracted from Steam product reviews. Each user in Steam can post one review for one product. Reviews themselves don't have unique Steam keys, but they can be uniquely identified by combining user ID and product ID. However, in our database, we assign a new unique key for every review to simplify data manipulation within our application. We also maintain a separateusertable to store some basic user information. - News tables (explained later) - These include
newsandntagtables used to store news published by authors of the product.
Tables related to scraping
Scraping products typically takes a few hours, while reviews can take considerably longer, especially on single machine. To handle potential interruptions, a mechanism was implemented, that resumes review scraping from the last known point.
Here's how it works:
- When we access a URL for reviews, we receive a response containing a batch of reviews along with a link to the next batch.
- Each review is stored in the
reviewtable, while information about the scraped batch, including the link to it, is stored in therscrapetable. - When a product's reviews are fully scraped (indicated by the absence of a "next batch" link), a
reviews_scrapedvalue in theproducttable is set to the current date and time. This timestamp helps identify completed products.
This mechanism enables us to skip scraping products that were already processed by checking the reviews_scraped value. It also allows us to resume from the most recent batch retrieved before interruption, by looking for the latest entry in rscrape table, related to unfinished product.
While Steam's pagination system might appear to use standard parameters like itemspage and numperpage, these are actually irrelevant. Instead, Steam relies on a custom cursor system for navigating review pages. This means you need to use the specific cursor value provided by the previous page in userreviewcursor parameter to access the next one. Because the data might change while we scrape, it is possible that we get cursor that is invalid. In that case, we have to repeat scraping for the whole product. Since this issue is rare, I did not address it further and am ok with some products not being scraped completely.
Scrapy pipelines
In Scrapy, item pipelines are designed for post-processing scraped data. They operate on each item extracted by the spider, allowing you to perform various tasks after the core scraping logic. Common use cases for item pipelines include cleaning, validation, deduplication and storage in databases.
Similar to middlewares, item pipelines are activated through an ITEM_PIPELINES setting. This is a dictionary where keys are the paths to your custom pipeline classes and the values are priority numbers that determine the order of execution. This allows you to chain multiple pipelines together to perform a sequence of post-processing steps.
Example
In the steam/settings.py file, we include the following setting to activate the SQLitePipeline:
ITEM_PIPELINES = {
'steam.pipelines.SQLitePipeline': 300,
}
The function that is responsible for processing scraping result is called process_item. In our case, this is where we store data into the database:
class SQLitePipeline:
@staticmethod
def process_item(item, spider):
if spider.name == 'products':
spider.db.add_product(item)
if spider.name == 'reviews':
spider.db.add_review(item, str(dt.datetime.today()), spider.review_ids, spider.rscrape_ids, spider.user_ids)
return item
The function checks the spider name and calls the appropriate method to add product or review to the database. The Scrapy documentation provides more details on pipeline functionality.
Using a web api for news
The Steam Web API allows you to fetch various kinds of product data, including user stats, user information and product news. While an API key is typically required for most functionalities, fetching news appears to be an exception, as documented in detailed documentation.
Example
The script for fetching news using the Steam Web API is located in scripts/get_news_api.py. This script is typically run after scraping reviews, because it retrieves news for products that already have reviews in the database.
Here's the core section of the script that downloads and stores news data:
url_string = f"http://api.steampowered.com/ISteamNews/GetNewsForApp/v0002/?appid={product_id}&count=20000&maxlength=20000&format=json"
with urllib.request.urlopen(url_string) as url:
data = json.load(url)
for item in data['appnews']['newsitems']:
db.add_news(item, tags)
db.commit()
Conclusion
The blog post builds upon the original blog by identifying and correcting sections of code required to get the scraper functioning again. It expands on the original code by including additional news data and storing it by using Scrapy pipelines and SQLite database.
If you're looking for debugged code only, you can access it on updated_original branch. The complete code is available on the master branch.
I hope this revised version proves helpful to those who encountered issues with the original scraping code. My experience with Scrapy has been very educational. I've gained a deeper understanding of the challenges associated with scraping and the advantages of using APIs.
This is the first actual blog I have ever written, so if you have any suggestions, or you found some explanations lacking, please let me know!